HBase產(chǎn)品新篇章 云原生多模數(shù)據(jù)庫Lindorm技術解析與數(shù)據(jù)處理服務實踐
在當今數(shù)據(jù)驅(qū)動的時代,企業(yè)面臨著數(shù)據(jù)量激增、數(shù)據(jù)類型多樣以及成本控制等多重挑戰(zhàn)。傳統(tǒng)的數(shù)據(jù)庫解決方案往往在“存得起”與“看得見”之間難以兼顧。HBase作為經(jīng)典的分布式列存儲數(shù)據(jù)庫,以其強大的海量數(shù)據(jù)存儲與高并發(fā)讀寫能力著稱。而阿里云基于HBase內(nèi)核深度優(yōu)化,推出的云原生多模數(shù)據(jù)庫Lindorm,則進一步解決了多模態(tài)數(shù)據(jù)處理、彈性伸縮與成本效率等核心痛點,真正實現(xiàn)了讓數(shù)據(jù)“既存得起,又看得見”。
一、 從HBase到Lindorm:云原生多模數(shù)據(jù)庫的演進
HBase的設計初衷是應對海量結構化與非結構化數(shù)據(jù)的存儲與隨機實時訪問。它基于HDFS,具備良好的水平擴展性和高可用性。在云原生與多模融合的趨勢下,企業(yè)需求變得更加復雜:需要同時處理時序數(shù)據(jù)、時空數(shù)據(jù)、寬表數(shù)據(jù)、文檔數(shù)據(jù)等多種模型,并要求極致的彈性與更低的成本。
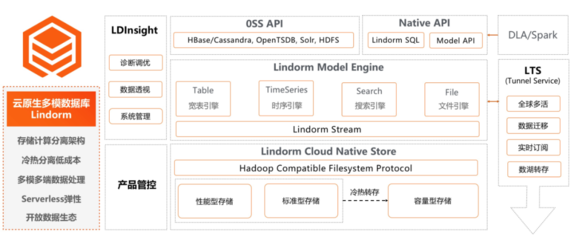
Lindorm應運而生,它繼承了HBase的高性能、高可靠基因,并進行了全面的云原生架構重構。其核心在于“多模”:一個數(shù)據(jù)庫引擎,原生支持寬表、時序、文件、搜索等多種數(shù)據(jù)模型,統(tǒng)一了數(shù)據(jù)入口,簡化了技術棧。這使得開發(fā)人員無需為不同類型的數(shù)據(jù)部署和維護多套系統(tǒng),極大地降低了運維復雜度和總擁有成本(TCO),從根本上讓海量數(shù)據(jù)“存得起”。
二、 Lindorm核心技術解析:如何讓數(shù)據(jù)“看得見”
“看得見”意味著數(shù)據(jù)不僅要存得好,更要能用得好,即具備高效的數(shù)據(jù)處理與服務能力。Lindorm通過一系列技術創(chuàng)新實現(xiàn)了這一點:
- 存儲計算分離與彈性伸縮:Lindorm采用徹底的存儲計算分離架構。數(shù)據(jù)持久化存儲在分布式存儲層(基于盤古),而計算節(jié)點(如讀寫節(jié)點、索引節(jié)點)則無狀態(tài)化,可根據(jù)業(yè)務負載秒級彈性擴縮容。這使得企業(yè)無需為業(yè)務峰值預置大量資源,真正按需使用,成本可控。當需要執(zhí)行復雜查詢或分析時,可以快速擴容計算資源,讓數(shù)據(jù)快速“可見”。
- 多模統(tǒng)一查詢與索引:Lindorm內(nèi)置了強大的二級索引(全局索引、局部索引)和搜索引擎(與阿里云Elasticsearch深度集成)。對于寬表數(shù)據(jù),除了主鍵查詢,可以通過二級索引實現(xiàn)靈活的多條件組合查詢。對于時序數(shù)據(jù),提供了高效的時序聚合查詢。更重要的是,它支持跨模型的統(tǒng)一查詢,例如將設備元數(shù)據(jù)(寬表)與其實時上報的指標數(shù)據(jù)(時序)進行關聯(lián)分析,極大提升了數(shù)據(jù)價值的挖掘效率。
- 高性能與智能優(yōu)化:Lindorm在HBase內(nèi)核上做了深度優(yōu)化,包括自研的LSM-Tree存儲引擎、智能壓縮編碼、冷熱數(shù)據(jù)分層等。通過智能緩存、謂詞下推、向量化計算等技術,大幅提升了查詢性能,尤其是復雜掃描和分析查詢的速度,讓大數(shù)據(jù)量的實時洞察成為可能。
- 無縫集成的數(shù)據(jù)處理服務:Lindorm并非孤立的存儲系統(tǒng),它提供了豐富的數(shù)據(jù)處理與服務鏈路。
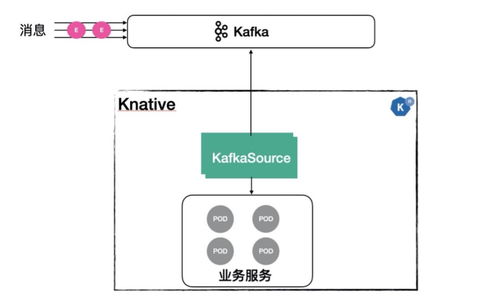
- 數(shù)據(jù)通道:支持通過DTS、Canal等工具與MySQL、Oracle等傳統(tǒng)數(shù)據(jù)庫進行實時同步,也支持Kafka、Flink等流計算引擎直接接入,實現(xiàn)流批一體的數(shù)據(jù)入庫。
- 計算生態(tài)集成:與Spark、Flink、Hive等大數(shù)據(jù)計算引擎無縫對接,方便進行離線數(shù)據(jù)分析、機器學習等深度數(shù)據(jù)加工。
- 數(shù)據(jù)服務化:通過HTTPSQL、JDBC等標準接口,或與API網(wǎng)關結合,能夠?qū)?shù)據(jù)庫中存儲的數(shù)據(jù)快速、安全地以API的形式暴露給前端應用,直接驅(qū)動業(yè)務,完成從數(shù)據(jù)存儲到數(shù)據(jù)服務的閉環(huán)。
三、 典型應用場景與數(shù)據(jù)處理服務實踐
Lindorm的“存得起、看得見”特性,使其在物聯(lián)網(wǎng)、金融、車聯(lián)網(wǎng)、互聯(lián)網(wǎng)內(nèi)容等領域大放異彩。
- 物聯(lián)網(wǎng)平臺:作為設備元數(shù)據(jù)、時序指標數(shù)據(jù)的統(tǒng)一存儲。海量設備數(shù)據(jù)以低成本存入,通過時序聚合查詢實時監(jiān)控設備狀態(tài),利用流計算(Flink)在Lindorm上實現(xiàn)實時告警,并通過數(shù)據(jù)服務API將分析結果推送到運維大屏。
- 內(nèi)容推薦與搜索:存儲用戶畫像(寬表)、內(nèi)容元數(shù)據(jù)(寬表/文檔)和行為日志(時序)。利用Lindorm的搜索索引實現(xiàn)內(nèi)容的全文檢索和多維度篩選,結合用戶實時行為進行在線特征計算,為推薦引擎提供毫秒級延遲的數(shù)據(jù)服務。
- 金融風控:存儲交易流水、用戶賬戶信息。利用二級索引快速定位可疑交易,通過Spark進行離線批量風險建模,模型結果回寫至Lindorm,為在線風控系統(tǒng)提供實時查詢服務。
###
云原生多模數(shù)據(jù)庫Lindorm,代表了大數(shù)據(jù)存儲與處理技術的一個重要發(fā)展方向。它根植于HBase的堅實土壤,通過云原生、多模融合、存算分離、智能索引等關鍵技術,構建了一個高彈性、低成本、強性能的統(tǒng)一數(shù)據(jù)底座。這不僅解決了海量數(shù)據(jù)“存得起”的經(jīng)濟性問題,更通過強大的內(nèi)置處理能力和開放的計算生態(tài),讓數(shù)據(jù)價值能夠被高效地“看得見”、用得上,賦能企業(yè)構建敏捷、智能的數(shù)據(jù)驅(qū)動型應用。在數(shù)字化轉型的深水區(qū),Lindorm這樣的技術正成為企業(yè)釋放數(shù)據(jù)潛能的關鍵基礎設施。
如若轉載,請注明出處:http://m.kuiyum.com/product/80.html
更新時間:2026-05-10 09:39:31